
El concepto de Data Lakehouse ha revolucionado la manera en que las empresas gestionan y procesan sus datos, combinando las capacidades de los Data Lakes y los Data Warehouses para ofrecer una arquitectura flexible y eficiente. En plataformas como Azure, esta arquitectura puede ser implementada utilizando una variedad de servicios que no solo permiten el almacenamiento y procesamiento de datos masivos, sino también la integración de herramientas de inteligencia artificial (IA) y machine learning (ML).
Además, con la integración de servicios como Azure Databricks, las empresas pueden aprovechar un enfoque multicloud, permitiendo el procesamiento de datos en diferentes plataformas como AWS, Google Cloud, y Azure, mientras se asegura una gobernanza centralizada y un soporte constante para tecnologías clave como Apache Spark.
¿Qué es un Data Lakehouse?
Un Data Lakehouse es una arquitectura moderna de datos que combina las características de un Data Lake y un Data Warehouse. Los Data Lakes se utilizan para almacenar grandes volúmenes de datos sin estructurar, mientras que los Data Warehouses están diseñados para datos estructurados y permiten realizar análisis más eficientes. El Data Lakehouse toma lo mejor de ambos mundos, permitiendo almacenar datos de manera flexible y procesarlos a escala para análisis avanzados.
Este enfoque es ideal para empresas que necesitan manejar datos de múltiples fuentes, que van desde datos no estructurados (imágenes, logs, archivos de audio) hasta datos transaccionales estructurados.
El papel de Azure Databricks en un enfoque multicloud
Uno de los componentes clave para la implementación de un Data Lakehouse en Azure es Azure Databricks, un servicio gestionado basado en Apache Spark. Lo que distingue a Databricks es su capacidad para operar de manera efectiva en entornos multicloud, ya que es compatible con AWS, Azure y Google Cloud. Esta flexibilidad es crítica para las empresas que buscan aprovechar diferentes nubes según sus necesidades sin tener que modificar su arquitectura de datos.
Azure Databricks también ofrece una evolución constante de Spark, proporcionando un entorno optimizado para tareas de procesamiento masivo, machine learning y análisis avanzado de datos. Además, cuenta con características avanzadas de gobernanza de datos, que facilitan el control del acceso, la auditoría y la seguridad en entornos complejos.
Servicios de Azure para crear un Data Lakehouse
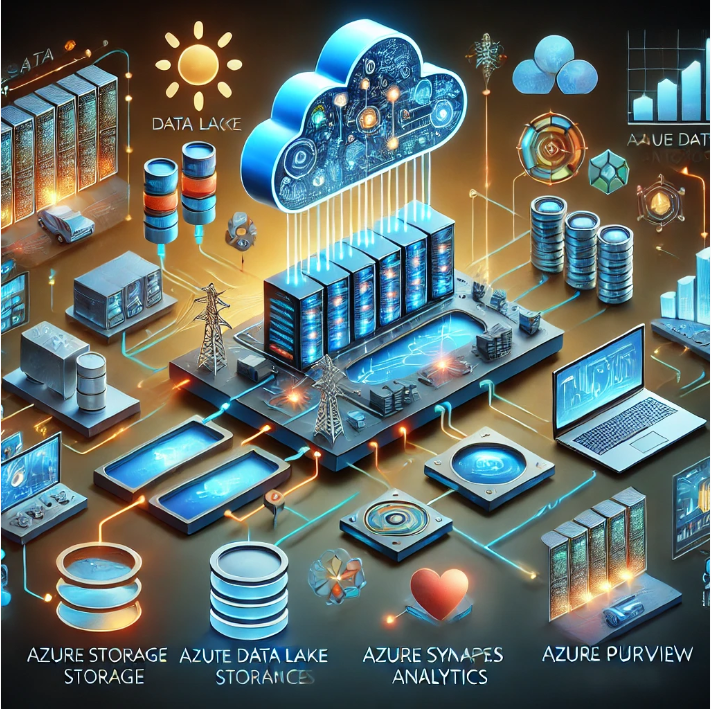
Para implementar un Data Lakehouse en Azure, se pueden utilizar varios servicios nativos que cubren las diferentes necesidades de almacenamiento, procesamiento, gobernanza y machine learning. A continuación, describo los servicios clave que forman parte de una arquitectura de referencia:
1. Almacenamiento de datos: Azure Data Lake Storage Gen2
El componente base de cualquier Data Lakehouse es el almacenamiento masivo de datos. Azure Data Lake Storage Gen2 (ADLS Gen2) es la opción ideal en Azure para manejar tanto datos estructurados como no estructurados. ADLS Gen2 proporciona almacenamiento escalable y seguro, optimizado para el análisis de datos.
- Características clave: Escalabilidad masiva, seguridad granular mediante control de acceso basado en roles (RBAC), y capacidades de gestión de grandes volúmenes de datos con rendimiento optimizado.
- Uso: En esta arquitectura, ADLS Gen2 actúa como el almacén principal para datos crudos o transformados.
2. Procesamiento de datos: Azure Databricks y Apache Spark
Azure Databricks se integra directamente con Azure Data Lake Storage y otros servicios en la nube, permitiendo el procesamiento de datos en tiempo real y en lotes (batch). Su motor basado en Spark permite ejecutar cargas de trabajo masivas con alta eficiencia y rendimiento.
- Características clave: Soporte para Spark, MLlib para machine learning, capacidad multicloud, y notebooks colaborativos para análisis de datos.
- Uso: Databricks se utiliza para procesar y transformar los datos almacenados en ADLS Gen2, creando datos estructurados listos para análisis avanzados.
3. Gobernanza y control: Azure Purview
La gobernanza de datos es esencial para cualquier arquitectura de datos moderna. Azure Purview es el servicio nativo de Azure diseñado para gestionar la gobernanza y el catálogo de datos en toda la organización. Purview permite a las empresas descubrir y clasificar los datos, aplicar políticas de acceso y llevar un control detallado del linaje de los datos.
- Características clave: Descubrimiento automático de datos, clasificación de datos sensibles, y capacidad para auditar el uso de datos.
- Uso: Azure Purview asegura que los datos dentro del Data Lakehouse estén bien gestionados y que se cumplan las normativas de privacidad y seguridad.
4. Análisis y consultas: Azure Synapse Analytics
Azure Synapse Analytics es el componente de análisis de la arquitectura de Data Lakehouse. Synapse permite ejecutar consultas SQL sobre grandes volúmenes de datos almacenados en ADLS Gen2, así como análisis avanzados que integran datos estructurados y no estructurados.
- Características clave: Unificación de Data Lake y Data Warehouse, integración con Spark y Power BI, y análisis masivo de datos a través de consultas SQL y Spark.
- Uso: En esta arquitectura, Synapse facilita el análisis rápido de grandes volúmenes de datos, transformándolos en insights accionables.
5. Machine Learning: Azure Machine Learning
Para tareas avanzadas de machine learning dentro del Data Lakehouse, Azure ofrece Azure Machine Learning, un servicio que facilita la creación, entrenamiento e implementación de modelos de machine learning a gran escala. Se integra con Databricks y otros servicios de datos en Azure.
- Características clave: Entrenamiento distribuido de modelos, integración con Spark y Databricks, y capacidad para implementar modelos en producción.
- Uso: Azure Machine Learning se utiliza para desarrollar e implementar modelos predictivos basados en los datos procesados en el Data Lakehouse.
Arquitectura de referencia para un Data Lakehouse en Azure
A continuación, se detalla una arquitectura de referencia para la implementación de un Data Lakehouse en Azure:
- Ingesta de datos: Los datos pueden ser ingeridos desde múltiples fuentes (bases de datos, aplicaciones empresariales, dispositivos IoT, archivos, etc.) hacia Azure Data Lake Storage Gen2 para su almacenamiento.
- Procesamiento y transformación: Utilizando Azure Databricks, los datos son procesados en tiempo real o por lotes (batch), transformándolos en datos estructurados listos para su análisis.
- Gobernanza de datos: A través de Azure Purview, se garantiza que todos los datos sean catalogados, clasificados y gestionados de acuerdo con las normativas de seguridad y privacidad.
- Análisis: Con Azure Synapse Analytics, los datos pueden ser consultados mediante SQL o Spark para generar insights en tiempo real, integrándose con Power BI para crear dashboards interactivos.
- Machine Learning: Azure Machine Learning se utiliza para crear y entrenar modelos predictivos que utilizan los datos procesados, proporcionando predicciones accionables basadas en los datos del Lakehouse.
- Visualización y acciones: Herramientas como Power BI o aplicaciones personalizadas permiten visualizar los insights obtenidos del Data Lakehouse y tomar decisiones empresariales basadas en datos en tiempo real.
Beneficios de un Data Lakehouse en Azure
- Escalabilidad y flexibilidad: Con servicios como Azure Databricks y Azure Data Lake Storage, las empresas pueden escalar su arquitectura a medida que sus necesidades de datos crecen, gestionando tanto datos estructurados como no estructurados.
- Gobernanza centralizada: Azure Purview permite una gobernanza de datos efectiva, asegurando que todos los datos estén bajo control, lo que es esencial para cumplir con normativas como GDPR.
- Multicloud con Databricks: La capacidad de Databricks para operar en un entorno multicloud permite a las empresas evitar el vendor lock-in y elegir la mejor plataforma según sus necesidades específicas.
- Análisis avanzado y machine learning: La integración de Synapse Analytics y Azure Machine Learning permite realizar análisis avanzados y desarrollar modelos predictivos con facilidad, lo que acelera la toma de decisiones basadas en datos.
Conclusión
La implementación de un Data Lakehouse en Azure permite a las empresas manejar grandes volúmenes de datos de manera eficiente, asegurando una integración fluida entre almacenamiento, procesamiento y análisis avanzado. Con herramientas como Azure Databricks, Azure Synapse Analytics, y Azure Machine Learning, es posible aprovechar un enfoque multicloud y desarrollar una arquitectura flexible que escala junto con las necesidades de la empresa. Además, servicios como Azure Purview aseguran que los datos sean gestionados y gobernados correctamente, manteniendo la seguridad y el cumplimiento normativo.

